


Introduction
In the world of data analytics, we often encounter challenges that test our understanding of data manipulation and SQL querying skills. One such interesting problem is tracking the start and final locations of a customer’s travel journey while calculating the total unique places they have visited. This blog post will guide you through solving this tricky SQL problem step-by-step using T-SQL, ensuring a solid understanding of the concepts involved.
Problem Statement
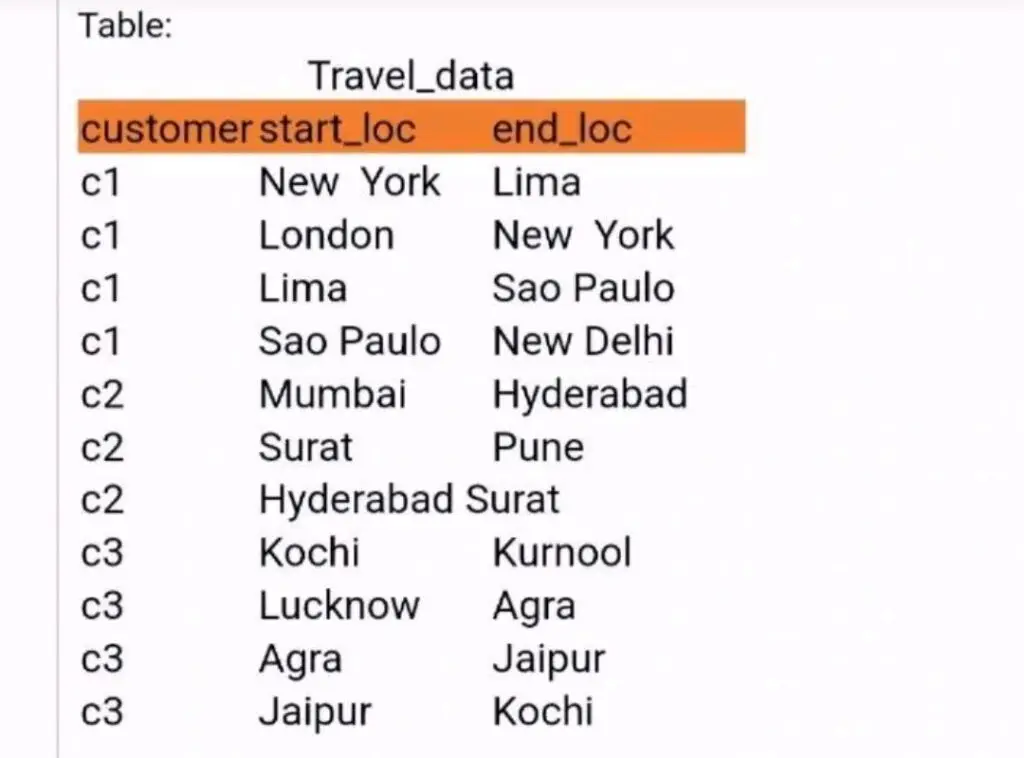
Given a table of customer travel data with each row representing a journey from a start_loc (starting location) to an end_loc (ending location), the task is to:
1.Identify the start location where each customer’s journey begins.
2. Identify the final location where the journey ends.
3.Calculate the total number of unique locations each customer has visited.
The output should be a summary table showing:
1. The customer ID
2. The initial start location of the journey
3.The final destination
4.The total number of unique locations visited

1. Understanding the Journey:
To solve this problem, we need to understand the flow of each customer’s journey:
Start Location: This is the first location in the journey and is not an end_loc in any of the customer’s trips.
Final Location: This is the final destination and is not a start_loc in any of the customer’s trips.
Total Visited: Count of all distinct locations (both start_loc and end_loc) for each customer.
Sql Projects :
-- Create the Travel_data table
CREATE TABLE Travel_data (
customer VARCHAR(10),
start_loc VARCHAR(50),
end_loc VARCHAR(50)
);
-- Insert sample data into the Travel_data table
INSERT INTO Travel_data (customer, start_loc, end_loc)
VALUES
('c1', 'New York', 'Lima'),
('c1', 'London', 'New York'),
('c1', 'Lima', 'Sao Paulo'),
('c1', 'Sao Paulo', 'New Delhi'),
('c2', 'Mumbai', 'Hyderabad'),
('c2', 'Surat', 'Pune'),
('c2', 'Hyderabad', 'Surat'),
('c3', 'Kochi', 'Kurnool'),
('c3', 'Lucknow', 'Agra'),
('c3', 'Agra', 'Jaipur'),
('c3', 'Jaipur', 'Kochi');
Step-by-Step Solution
To achieve the above goals, we can break down the task into three main sub-queries using Common Table Expressions (CTEs):
Step 1: Identify Start Locations We identify the start location for each customer by selecting start_loc that is not listed as an end_loc for the same customer:
Here we will use use CTE and join table with itself to get the start_loc that are not in end_loc list.
WITH StartLocations AS (
SELECT
customer,
start_loc
FROM Travel_data t1
WHERE
NOT EXISTS (
SELECT 1
FROM Travel_data t2
WHERE t2.customer = t1.customer
AND t2.end_loc = t1.start_loc
)
)
---Check the Output of that Part
SELECT * FROM StartLocations Step 2: Identify Final Locations Similarly, we identify the final locations by selecting end_loc that is not listed as a start_loc for the same customer:
WITH FinalLocations AS (
SELECT
customer,
end_loc
FROM
Travel_data t1
WHERE
NOT EXISTS (
SELECT 1
FROM Travel_data t2
WHERE t2.customer = t1.customer
AND t2.start_loc = t1.end_loc
)
)
---Check the Output of that Part
SELECT * FROM FinalLocations Sql Practice Questions :
Step 3: Count Total Unique Locations Visited Combine start_loc and end_loc for each customer, and count distinct locations using a UNION to eliminate duplicates:
WITH TotalVisits AS (
SELECT
customer,
COUNT(loc) AS total_visited
FROM (
SELECT
customer,
start_loc AS loc
FROM Travel_data
UNION
SELECT
customer,
end_loc AS loc
FROM Travel_data
) AS combined
GROUP BY customer
)
---Check the Output of that Part
SELECT * FROM TotalVisits Final Output: Join the results of the above CTEs to generate the final output:
WITH StartLocations AS (
SELECT
customer,
start_loc
FROM Travel_data t1
WHERE
NOT EXISTS -----Start_loc should not be in end_loc Column
( SELECT 1
FROM Travel_data t2
WHERE t2.customer = t1.customer
AND t2.end_loc = t1.start_loc
)
),
FinalLocations AS (
SELECT
customer,
end_loc
FROM Travel_data t1
WHERE
NOT EXISTS -----end_loc should not be in start_loc Column
( SELECT 1
FROM Travel_data t2
WHERE t2.customer = t1.customer
AND t2.start_loc = t1.end_loc
)
),
TotalVisits AS (
SELECT
customer,
COUNT(loc) AS total_visited
FROM (
SELECT
customer,
start_loc AS loc
FROM Travel_data
UNION ---To Remove Duplicates
SELECT
customer,
end_loc AS loc
FROM Travel_data
) AS combined
GROUP BY customer
)
SELECT
s.customer,
s.start_loc AS start_loc,
f.end_loc AS final_loc,
t.total_visited
FROM StartLocations s
INNER JOIN FinalLocations f ON s.customer = f.customer
INNER JOIN TotalVisits t ON s.customer = t.customer;
Conclusion
This problem demonstrates the power of SQL in solving complex data manipulation tasks. By carefully structuring our queries using CTEs, we were able to trace the customer journeys accurately, identify their start and end points, and count the total locations they visited. Whether you’re working with travel data or any other form of sequential data, these techniques can be invaluable in deriving meaningful insights from your datasets.






Leave a Reply